Today, we will be using the text editor atom and a terminal with ipython running.
atom and ipython side by side
Today, we will be using the text editor atom and a terminal with ipython running.
atom and ipython side by side
Python’s language can be augmented by new functions and object from modules (or packages, or libraries). They are imported with the function import.
Example 1 (in ipython command line):
import math
math.sin(1.3)Example 2:
import numpy as np
import matplotlib.pyplot as plt
plt.plot(np.sin(np.linspace(0, 6*np.pi, 500)))
plt.show()Example 3:
import random
random.<TAB>
random?Python comes with a standard library of modules: https://docs.python.org/2/library/index.html
Anaconda comes with more libraries pre installed: https://docs.continuum.io/anaconda/pkg-docs
It is easy to create one’s own module: having a file mymodule.py in the current directoy, it is possible to use import mymodule.
Have a look at the turtle module https://docs.python.org/2/library/turtle.html
EX: Write the following program in atom, save it and execute it
import turtle
turtle.forward(100)
turte.left(120)
turtle.forward(100)
turtle.left(120)
turtle.forward(100)
turtle.left(120)
turtle.mainloop()EX: Modify this program to display a regular polygon with n sides
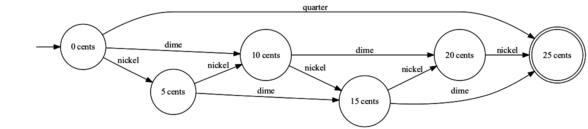
The coin-counter
The input is a list a coins, e.g., ‘dime’, ‘quarter’, ‘nickel’ and the program must write ‘ok’ if the sequence leads to the correct amount (25 cents).
Given the following function:
def is_factor(a, b):
return b % a == 0
print(is_factor(3, 27))
print(is_factor(3, 28))Write a program that determines prime numbers between 1 and 100
Remember that a number represented by four digits “d3 d2 d1 d0” in a basis ‘b’, has a value of d3b^3 + d2b^2 + d1b^1 + d0b^0
To learn more about how integer numbers are represented in binary format, you can check out http://csunplugged.org/binary-numbers
Convert (manually) into decimal the following binary numbers: - 101 - 1000 - 1011 - 11111111
Answer: 101 = 5, 1000 = 8, 1011 = 11, 11111111 = 255
Let us write a function that, given the binary representation of a number as a string of ‘0’ and ‘1’, returns its value as a integer.
y 1. Let us first suppose that we want to convert a string containing exactly 8 binary digits (e.g. ‘01011010’) into decimal. How would you do that?
. . .
Here is a proposal:
def todec8bits(s):
return int(s[0])*128 + int(s[1])*64 + int(s[2])*32 + \
int(s[3])*16 + int(s[4])*8 + int(s[5])*4 + \
int(s[6])*2 + int(s[7])
todec8bits("01010101")And another solution which demonstrates several Pythonic constructions that we have not seen yet:
pow2 = [2 ** n for n in range(7, -1, -1)]
n = 0
for b, p in zip(s, pow2):
n += int(b) * p
print(n)Can you see see why it works?
. . .
The previous codes had an issue: they only worked for numbers with exactly 8 bits:
todec8bits("0101010")
todec8bits("010101010")We should modify it to adapt to the size of the string ‘s’.
Can you try? . . .
Here is a possible solution:
def todec(s):
""" convert a string of 0 and 1 representing a binary number into an integer """
n = 0
for b in s:
n = n * 2 + int(b)
return n
for i in ['101', '1000', '1011', '11111111']:
print(todec(i))Now we will go in the other direction: Our aim is to write a program that, given a number (in decimal), computes its binary representation.
If you have an idea how to program it, please proceed. If not, we propose that you follow the following steps:
Study the program below. Execute it with various values of the variable num. Do you understand the last line? Do you see a limitation of this program?
num = 143
d3 = int(num/1000) % 10 # thousands
d2 = int(num/100) % 10 # hundreds
d1 = int(num/10) % 10 # dec
d0 = num % 10
print(str(d3) + str(d2) + str(d1) + str(d0)). . .
num = 17
b0 = num % 2
b1 = int(num/2) % 2
b2 = int(num/4) % 2
b3 = int(num/8) % 2
b4 = int(num/16) % 2
b5 = int(num/32) % 2
b6 = int(num/64) % 2
b7 = int(num/128) % 2
b8 = int(num/256) % 2
print(str(b8) + str(b7) + str(b6) + str(b5) + str(b4) + str(b3) + str(b2) + str(b1) + str(b0)). . .
. . .
def tobin(num):
b7 = int(num/128) % 2
b6 = int(num/64) % 2
b5 = int(num/32) % 2
b4 = int(num/16) % 2
b3 = int(num/8) % 2
b2 = int(num/4) % 2
b1 = int(num/2) % 2
b0 = num % 2
return (str(b7) + str(b6) + str(b5) + str(b4) + \
str(b3) + str(b2) + str(b1) + str(b0))
for n in range(256):
print(n, tobin(n)). . .
(Advanced) Write an improved version that uses a loop and does not have a limitation in size.
. . .
def binary(n):
if n==0:
return "0"
s = ""
while n > 0:
b = str(n % 2)
s = b + s
n = n / 2
return s. . .
Study the following code. Do you understand why it works?
def binary(num):
if num == 0:
return "0"
if num == 1:
return "1"
return(binary(int(num /2)) + binary(num % 2))
print(binary(1234)). . .
Answer: It is a recursive function which calls itself. See http://en.wikipedia.org/wiki/Recursion_%28computer_science%29
. . .
A bit more about recursion:
The factorial of a integer number ‘n’ is the function that associate to n the product of 1, 2, …, n. Therefore f(n) = f(n-1) * n
Write a recursive function that computes factorial(n)
. . .
The Fibonacci sequence is such that:
u_0 = 1 u_1 = 1 u_n = u_{n-1} + u_{n-2}
Program a function that returns the ’n’th Fibonacci number.
. . .
To go further:
If you want to know how negative integer numbers are represented, see http://en.wikipedia.org/wiki/Two%27s_complement
Type 0.1 + 0.3 in the python console and be amazed. To understand what is going on, read [python’s doc about floats] (https://docs.python.org/2/tutorial/floatingpoint.htmlhttps://docs.python.org/2/tutorial/floatingpoint.html) and What Every Programmer Should Know About Floating-Point Arithmetic.
A text file is nothing but a sequences of characters.
For a long time, characters were encoded using ASCII code.
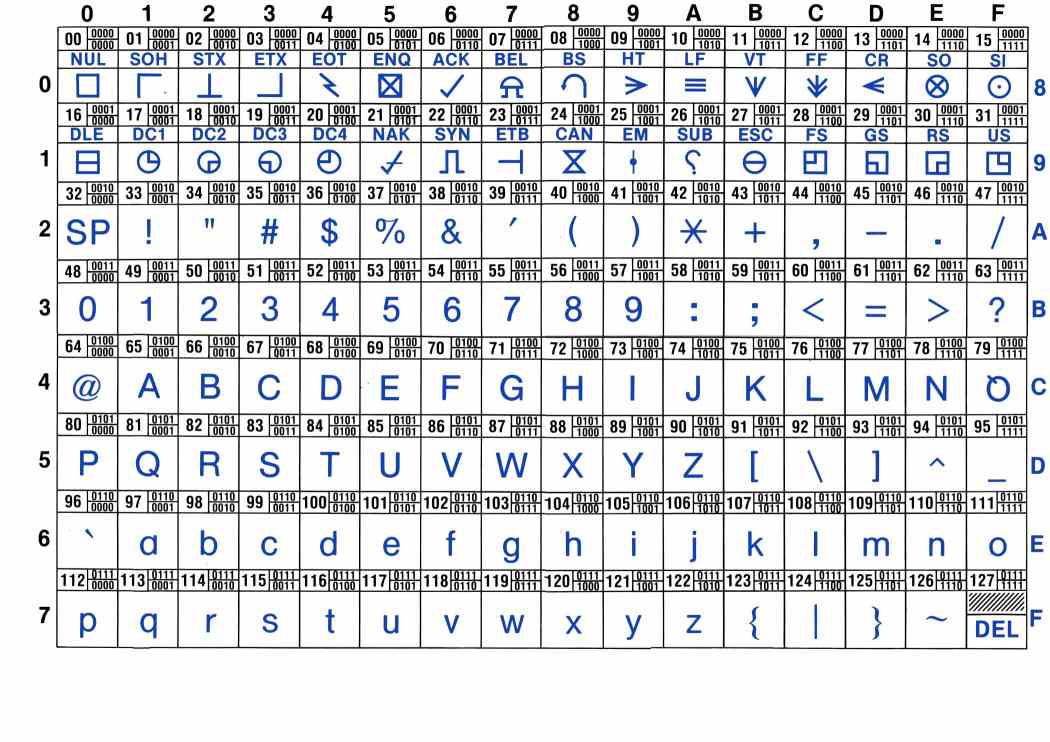
ascii table
In Python, you can know the code of a character with the function ord:
print(ord('a'))
print(ord('@'))The inverse of ord is chr.
chr function of Python to print it.For example, if you name is ‘ZOE’, you would type:
print(chr(90)+chr(79)+chr(69))Remark: ASCII codes use one byte (=8bits) per character. This is fine for English, but cannot cover all the caracters of all alphabets. It cannot even encode french accented letters.
Unicode was invented that associate a unique 2 bytes number to each character of any human script. It is possible to write text files using these number, but more economic to encode the most common letters with one byte, and keep the compatibility with ASCII (UTF-8).
print("".join([unichr(c) for c in range(20000, 21000)])))a = "Bonjour Jean"
len(a)
a[2:4]
a.replace("Jean", "Marc")
a
b = a.replace("Jean", "Marc")
a = "caillou, genou, bijou"
a.split(",")
b= ['alpha', 'beta', 'gamma']
";".join(b)mylist1 = ['alpha', 'beta', 'gamma']
mylist2 = [1, 2, 3]
for i in range(len(list1)):
print(mylist1[i], mylist2[i])Note: remember zip?
mydict = { 'alpha':1, 'beta':2, 'gamma':3}
for i, v in mydict:
print i, vYou can think of dictionaries as functions from keys to values.
Exercice: Given a list of words, write a program that find which are anagrams
…
def anagrams(wordlist):
anagrams = {}
for w in wordlist:
key = str(sorted(w))
if key in anagrams: anagrams[key].append(w)
else: anagrams[key] = [ w ]
return [ l for l in anagrams.itervalues() if len(l) > 1 ]
print(anagrams(['ab','ba','cd','ef','gh','hg']))Create a file containing a few lines of text with atom and save it under the name myfile.txt.
Execute the code:
inputFile = file(‘myfile.txt’)
for lines in inputFile:
print linesWrite a program count-words that counts the number of lines and the number of words in a text file.
Note: Use the module sys, and the variable sys.argvto read the name of the text file from the command line.
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import sys
def count_words(text):
nlines, nwords = 0, 0
for line in file(filename):
nlines += 1
nwords += len(line.split())
return (nlines, nwords)
if __name__ == '__main__':
fname = sys.argv[1]
text = file.fnames.readlines()
print(count_words(text))…
Ex: Write a program that computes the number of occurences of words in a text file
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import sys
def words_freq(text):
""" input:
text: a list of strings
output:
the number of occurences of each words in text
"""
freqs = {}
for l in text:
for w in l.strip().split():
if w in freqs:
freqs[w] += 1
else:
freqs[w] = 1
return freqs
if __name__ == '__main__':
fname = sys.argv[1]
text = file(fname).readlines()
print(words_freq(text))Ex: modify the preceding program to plot Zipf’s curve (see https://en.wikipedia.org/wiki/Zipf%27s_law)
Create a file zipf.py with the text below and import it in the preceding code.
import matplotlib.pyplot as plt
def zipf_plot(freqs):
""" input:
freqs: list of integers
output:
None
display Zipf's graphics (see https://en.wikipedia.org/wiki/Zipf%27s_law)
"""
n = sorted(freqs, reverse = True)
plt.figure()
plt.loglog()
plt.plot(n)
plt.show()sum = 0
for l in file('mynumbers.csv'):
l2 = l.strip() # remove end of line
if len(l2) > 0 : # avoid empty lines
c1, c2 = l2.split(',')
sum += float(c2)
print(sum)In real life, this kind of job is handled with the module pandas
f = pandas.read_csv('mynumbers.csv', header=None, delimiter=',')
f[1].sum()Download the file http://pallier.org/ressources/AIP2016/Info-2/EXERCICES-2/american-english.txt and find all the anagrams in English
A possible program follows, with is meant to be run on the command line with the argument american-english.txt.
#! /usr/bin/env python
# -*- coding: utf-8 -*-
import sys
def anagrams(wordlist):
""" input:
wordlist: a list of strings (words)
output:
a list of lists of words that have the same letters
"""
anagrams = {}
for w in wordlist:
key = str(sorted(w))
if key in anagrams: anagrams[key].append(w)
else: anagrams[key] = [ w ]
return [ l for l in anagrams.itervalues() if len(l) > 1 ]
if __name__ == '__main__':
# the input is a text file with one word per line
text = [ l.strip() for l in file(sys.argv[1]).readlines() if l != '\n']
print(anagrams(text))Exercice: modify the preceding program to read the file directly from the internet, using the module urllib2