|
|
Ce document est disponible en version pdf et en version html, ŗ partir de l'adresse http://www.pallier.org/ressources/
R est un logiciel pour l'analyse statistique des donnťes. Il fournit les procťdures usuelles (t-tests, anova, tests non paramťtriques...) et possŤde des possibilitťs graphiques performantes pour explorer les donnťes. Pouvant Ítre utilisť aussi bien en mode interactif qu'en mode batch, R est un logiciel libre, dont le code source est disponible et qui peut Ítre recopiť et diffusť gratuitement. Des versions compilťes de R sont disponibles pour Linux, Windows et Mac OS X.
Au moment de la rťdaction de ce document (Octobre 2004), la version courante de R est la 2.0.
Le site principal du logiciel R est www.r-project.org.
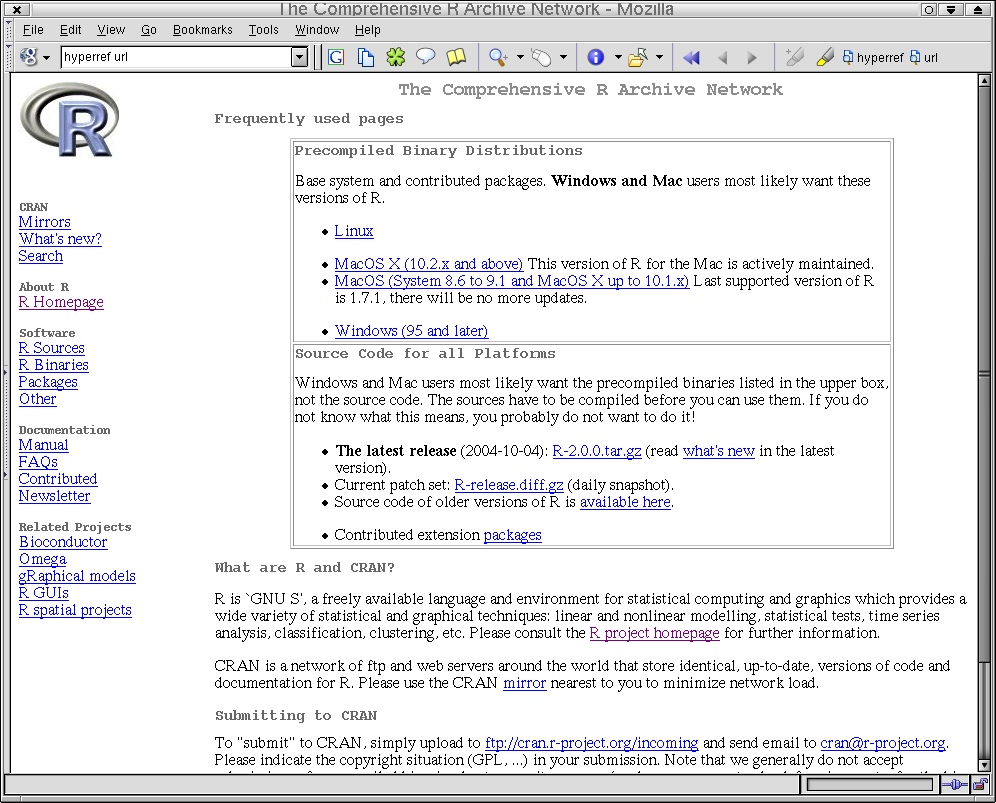
Le tťlťchargement de R se fait ŗ partir d'un des sites du ``Comprehensive R archive Network'' (CRAN), par exemple cran.cict.fr (cf. Fig. 1.1).
|
|
Installation sous Windows :
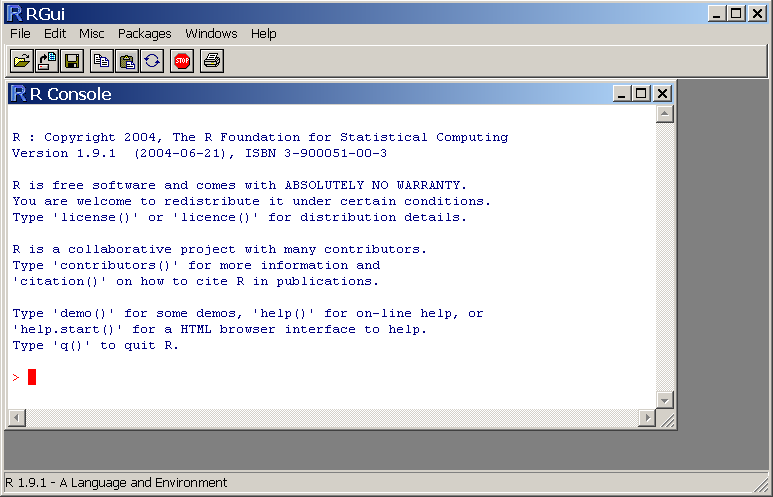
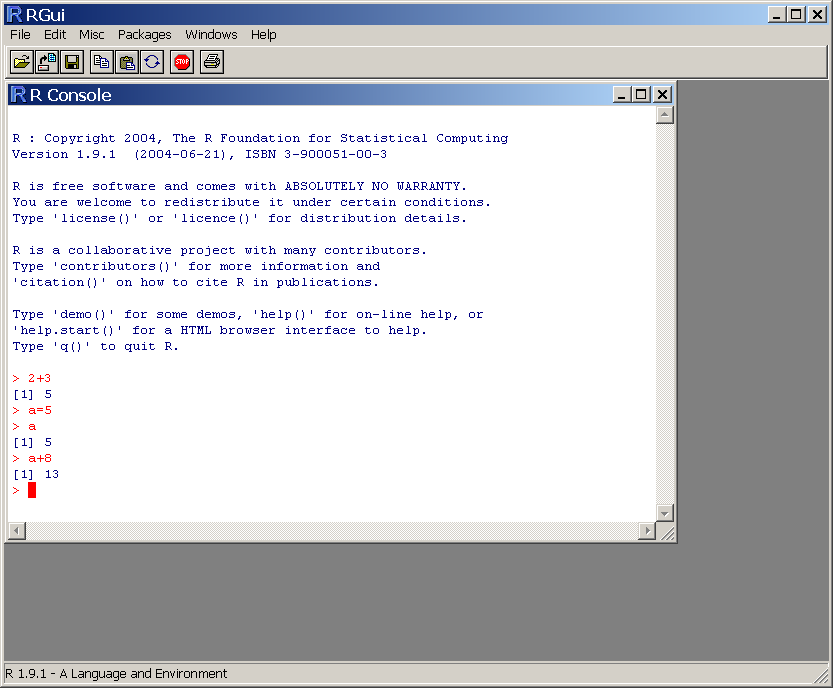
Le programme d'installation pour Windows est accessible en suivant les liens ``Windows'', puis ``Base''. Le nom de ce programme dťpend de la version, il s'agit, par exemple, de ``Rw2000.exe'' pour la version 2.0. Tťlťchargez ce fichier sur votre disque, puis cliquez-le pour installer le logiciel. Si vous acceptez l'option par dťfaut ``Create a desktop icon'', une icŰne reprťsentant une lettre ``R'' en bleu est ajoutťe sur le bureau. Cliquez dessus, pour voir apparaÓtre la fenÍtre 'RGui' (``R Graphical User Interface'', voir figure 1.2)
|
|
Installation sous Mandrake Linux :
Pour une installation sous Linux, vťrifiez s'il existe un paquetage ``rpm'' adaptť ŗ votre distribution et prÍt ŗ Ítre installť. Si tel est le cas, tťlťcharger-le et installez le, en tant qu'administrateur, avec la commande ``rpm -i R*.rpm''.
Si vous utilisez Mandrake Linux 10.x, R fait partie de la distribution de base (il est sur les CD), et il suffit de taper ``urpmi R-base'' pour l'installer.
En l'absence de binaire prťcompilť, il vous faudra rťcupťrer le code source (R-2.0.0.tar.gz) et le compiler avec une commande 'configure && make && make install' (en tant qu'utilisateur 'root'). Cela ne doit pas poser de problŤme mais nťcessite que les outils de compilation soient bien installťs sur votre systŤme (notamment le compilateur fortran g77).
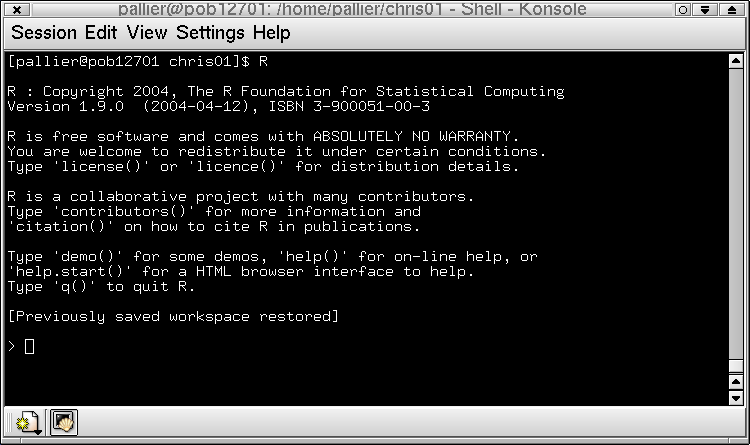
Pour lancer R sous Linux, il suffit de taper ``R'' dans un terminal (cf. Fig. 1.3).
|
|
AprŤs avoir installť le systŤme de base, vous pouvez installer des modules supplťmentaires, parfois appelťs ``paquetages'' (packages), qui ajoutent des fonctions ŗ R.
Pour l'analyse des donnťes d'expťriences, les paquetages car, gregmisc, vcd, psy, multcomp fournissent des fonctions supplťmentaires intťressantes. Par exemple, ``multcomp'' fournit diverses procťdures pour effectuer des comparaisons multiples (Dunnett, Tukey, Sequen, AVE, Changepoint, Williams, Marcus, McDermott, Tetrade).
Ces modules sont disponibles sur les sites CRAN dans la section ``Contributed extension packages''.
Pour installer un module sous Windows, dans RGui, utiliser le menu 'Package/Install package from CRAN' (il faut Ítre connectť a Internet).
Pour installer un module sous Linux, il faut d'abord tťlťcharger le fichier package.tar.gz du CRAN, puis, en tant que root, exťcuter:
R CMD INSTALL package.tar.gz
Rest un programme avec lequel on communique en tapant des commandes plutŰt qu'en cliquant dans des menus ou sur des icŰnes.
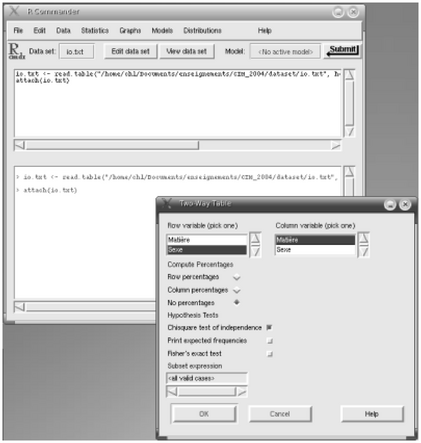
Il existe cependant des systŤmes ŗ bases de menu et d'icŰnes (des ``cliquodrŰmes'') qui gŤrent l'interaction avec R, et permettent, plus ou moins, d'ťviter de taper des commandes. Citons, entre autres, les interfaces graphiques ``Rcommander'' (Linux + Windows, cf. figure 1.4), et ``SciViews'' (Windows).
|
|
Nťanmoins, il nous paraÓt qu'apprendre les commandes de R permet de mieux comprendre ce qu'on fait et autorise finalement plus de flexibilitť. Pour ces TPs, nous avons fait le choix de vous enseigner les rudiments du langage R.
De nos jours, beaucoup de gens trouvent naturel de pouvoir utiliser les logiciels sans lire de documentation. Si cela est raisonnable pour les logiciels qui rťalisent des opťrations assez simples, c'est dangereux avec les logiciels qui effectuent des opťrations conceptuellement compliquťes. Dans le cas de R, qui comprend de nombreuses commandes, il est illusoire d''envisager utiliser ce logiciel sans lire un minimum de documentation. Notre expťrience est que les premiŤres heures d'analyse de donnťes avec R nťcessitent de frťquents recours aux documentations, mais lorsqu'on est devenu ŗ l'aise, alors il n'y a pratiquement plus besoin de s'y rťfťrer.
Il est donc utile de savoir oý chercher l'information a propos de R.
Pour les dťbutants, on trouve sur Internet un bon nombre de documents sur R, notamment dans la section ``Documentation/Contributed'' du site www.r-project.org. Mentionnons en particulier :
R possŤde aussi une documentation officielle, sous forme de fichiers pdf et html, qui est copiťe sur votre disque dur lors de l'installation du logiciel. Dans l'interface graphique sous Windows, les manuels au format pdf sont accessibles dans les menus Help/Manuals. Il est fortement conseillť de parcourir, au minimum, les deux documents ``An Introduction to R'' et ``R Data Import et Export''.
Les manuels sont ťgalement accessibles sous forme html, dans le menu Help/Html help sous Windows, et en tapant help.start() sous Linux. Cela ouvre votre navigateur Internet sur une page web locale qui contient divers liens, entre autres vers ces manuels. Par exemple, le lien Packages/base liste les commandes de bases de R.
Il existe plusieurs livres publiťs qui traitent de R. Pour les dťbutants, les deux livres suivants peuvent offrir une aide utile :
Pour un niveau plus avancť:
L'interaction avec R se fait en tapant des commandes dans la fenÍtre R Console.
Pour commencer, vous pouvez utiliser R comme une calculatrice. Cliquez dans la fenÍtre 'R Console', puis tapez:
2+3
Le rťsultat, '5', doit s'afficher.
Poursuivez avec:
a=5 a+8
RGui doit se prťsenter comme sur la Figure .
|
|
Le principe de R est le suivant : vous entrez une ligne de commande, et quand vous tapez sur 'Entrťe', R lit cette ligne et effectue l'opťration demandťe.
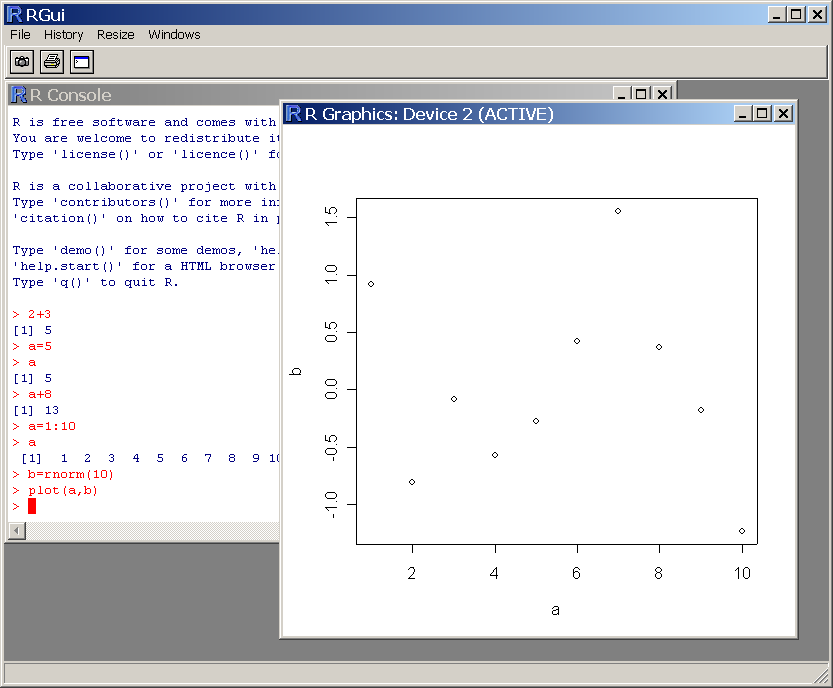
Essayez maintenant les commandes suivantes :
a=1:10 a b=rnorm(10) plot(a,b) plot(a,b,pch=16,col=2)
La commande plot provoque l'affichage d'une fenÍtre graphique (Fig. 2.2).
|
|
Cliquez ŗ nouveau dans la fenÍtre R Console, puis tapez:
a=c(3,4,6,7,8,9)
a
length(a)
b=c('alpha','beta')
b
length(b)
La variable 'a' contient un vecteur numťrique ŗ six ťlťments.
La variable 'b' contient un vecteur contenant deux chaÓnes de caractŤres.
Les concepts de vecteur et de variable sont essentiels dans R. On y reviendra plus tard ; pour le moment, retenez que :
Comme on l'a dťjŗ vu, la liste des variables peut Ítre affichťe par ``ls().'', et un variable peut Ítre dťtruite par la commande ``rm(nom)''.
Entrez les commandes suivantes, pas ŗ pas, et observez le rťsultats:
a=rnorm(20,mean=55,sd=10) mean(a) sd(a) max(a) summary(a) hist(a) boxplot(a) stripchart(a) stripchart(a,pch=16,cex=2,col=2,method='jitter',vertical=T) x1=rnorm(10,mean=100,sd=10) x2=rnorm(10,mean=110,sd=10) boxplot(x1,x2) t.test(x1,x2) plot(x1,x2) summary(lm(x2~x1)
A tout moment, une aide en ligne est disponible ŗ l'aide de la commande help.search('mot clť'). La description dťtaillťe d'une commande s'obtient en tapant `?nom_de_la_commande'.
Essayez :
?t.test
help.search("test")
help.start()
La fenÍtre ``R Console'' ťtant active, sťlectionnez ``File/Exit'' et rťpondez ``Oui'' ŗ la question ``Save workspace image?''
Et voilŗ...
Tout votre travail est-il perdu ?
Non. Redťmarrez R, et remarquez la ligne:
[Previously saved workspace restored]
Tapez ``ls()'' et constatez que vos variables sont toujours lŗ.
Le ``workspace'' (``espace de travail''), c'est ŗ dire l'ensemble des variables, a ťtť sauvegardť sur le disque. Cela permet de reprendre une analyse de donnťes au point oý on l'a laissťe quand on a quittť R.
Si vous voulez ``nettoyer'' le workspace, c'est ŗ dire supprimer toutes les variables qu'il contient, tapez la commande ``rm(list=ls())''.
Il est possible de choisir le nom de fichier oý est sauvegardť le workspace (par dťfaut ``.RData''). Cela permet de faire plusieurs analyses indťpendantes sans les mťlanger. (Voir les menus File/Load workspace/ Save Workspace). Une alternative plus recommandťe et de crťer un dossier pour chaque analyse de donnťes indťpendantes.
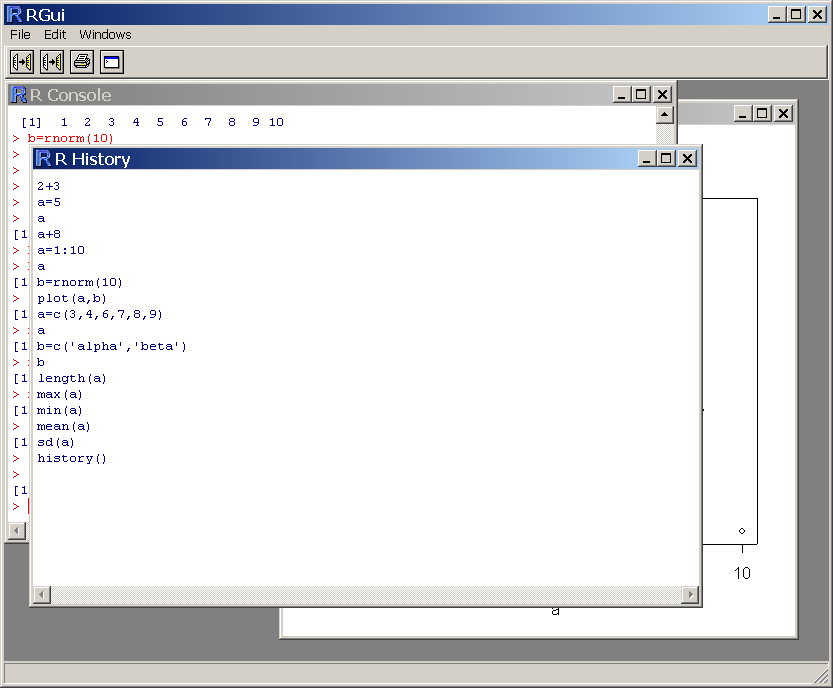
Tapez la commande history(). Une fenÍtre s'affiche listant les derniŤres commandes que vous avez tapťes (voir figure ).
|
|
La maniŤre la plus efficace de travailler avec R consiste ŗ sauvegarder les commandes au fur et ŗ mesure dans un fichier texte. Pour cela, en parallŤle avec R, ouvrez un ťditeur de fichier texte (le plus simple d'entre eux, bien qu'il soit trŤs limitť, est le bloc-notes de Windows disponible dans les accessoires).3
En utilisant le copier/coller, copier dans le fichier texte les commandes qui font l'essentiel de l'analyse. A la fin de votre session de travail, sauvez ce fichier avec un nom explicite (par exemple le nom de l'expťrience) et une extension ``.R''.
Quand vous reprendrez cette analyse quelques jours ou mois plus tard, vous pourrez rťutiliser ce fichier, qu'on appelle habituellement un script. R vous permettra de rť-executer les commandes de ce script en utilisant la commande source.
Faites un essai: crťez un fichier qui contient les lignes suivantes :
a=rnorm(100) b=rnorm(100) summary(a) summary(b) cor.test(a,b)
Sauvez-le dans ``Mes documents'', sous le nom ''test.R''.
Dans R, utilisez le menu ``File/Change Dir'' pour aller dans ``Mes Documents''. Puis tapez:
source('test.R',echo=T)
Vťrifiez que cela marche.
Sous Linux, il n'est pas nťcessaire de dťmarrer R: on peut entrer ``R BATCH script.R'' sur une ligne de commande dans un terminal et les rťsultats sont ťcrits automatiquement dans le fichier `script.Rout'.
Les commandes et les rťsultats des analyses statistiques et les graphiques peuvent Ítre copiťs/collťs dans un document.
Les rťsultats (sans les commandes) peuvent Ítre copiťs automatiquement dans un fichier texte gr‚ce ŗ ``sink''. Tapez:
sink('monanalyse.txt',split=T)
a=1:10
mean(a)
summary(a)
sink()
Puis ouvrez le fichier ``monanalyse.txt''.
Les graphiques peuvent Ítre sauvťs directement dans des fichiers graphiques en utilisant les commandes postscript, jpeg ou png (voir l'aide en ligne de ces fonctions).
Mentionnons le paquetage R2HTML qui permet de crťer des rapports au format html de faÁon semi-automotique.
L'expťrience prouve que la meilleure stratťgie est de crťer un rťpertoire (dossier) par analyse de donnťes, et d'y disposer: (a) les fichiers de donnťes brutes; (2) le fichier script contenant les commandes R; (3) le workspace et le(s) fichiers(s) rťsultats (textes et graphiques).
L'objet de base en R est le vecteur. Un vecteur peut contenir des valeurs numťriques, des valeurs de vťritť (True or False), des chaÓnes de caractŤres... Les fonctions les plus utilisťes pour crťer des vecteurs sont c, rep et seq :
c(1,2,3,4,5,6)
c(T,T,F,F)
c('a','b')
rep(55,10)
rep(c(1,2),10)
rep(c('a','b'),c(2,7))
seq(1,10,by=.1)
Un type de vecteur particuliŤrement utile est le type factor. Les facteurs sont des vecteurs utilisťs pour classifier les valeurs d'autres vecteurs (les facteurs sont des ``variables indicatrices''). Par exemple, ťtant donnť 100 scores provenant de plusieurs groupes de sujets, une variable facteur peut dťsigner ces sous-groupes.
(a=factor(c(rep('alpha',10),rep('beta',10))))
(b=gl(3,4,48,labels=c('a','b','c')))
(x=rnorm(48))
tapply(x,b,mean)
boxplot(x~b)
stripchart(x~b,method='jitter')
stripchart(x~b,method='jitter',vertical=T)
On peut crťer un facteur ŗ partir d'un vecteur gr‚ce ŗ la fonction factor, ou directement avec la fonction ``gl''.
(a=rnorm(50))
a[1]
a[2]
a[c(1,3,5)]
a>0
a[a>0]
(b=gl(2,25,labels=c('g1','g2')))
a[b=='g1']
Une particularitť de R est que les ťlťments d'un vecteur peuvent avoir des noms:
v=c(1,2,3,4)
names(v)=c('alpha','beta','gamma','delta')
v['beta']
Cela s'avŤre trŤs utile pour crťer des dictionnaires. Par exemple, un vecteur 'freq' donnant la frťquence d'usage des mots peut avoir les mots comme 'names' ; il suffit alors de taper ``freq['aller']'' pour obtenir la frťquence du mot 'aller'.
mots=c('aller','vaquer')
freq=c(45,3)
freq
freq[mots=='aller']
names(freq)=mots
freq
freq['aller']
D'autres objets de R sont les les listes, les arrays (vecteurs multidimensionnels) et les data.frames.
Les data.frames sont des listes de vecteurs qui ont tous la mÍme longueur. Les data.frames sont trŤs bien adaptťs pour stocker des donnťes prťsentťes sous forme de tableau bi-dimensionnel.
(a=array(1:20,dim=c(4,5)))
a[2,4]
(b=list(alpha=1:3,
beta=c('a','b','c','d')))
names(b)
b$alpha
b$beta
(c=data.frame(a=gl(2,5,10),b=1:10,x=rnorm(10)))
c$a
c$b
c$x
c[1:2,]
Les objets peuvent Ítre enregistrťs dans des variables avec l'opťrateur = (ou <-). Pour voir le contenu de l'objet reprťsentť par une variable, il suffit de taper le nom de celle-ci.
a<-c(1,2,3) a ls() rm(a) ls()
Les vecteurs contenus dans une liste ou dans un data.frame sont accessibles avec le symbole $. Un data.frame peut Ítre ``attachť'' pour que ses vecteurs soient directement accessibles.
mydata<-data.frame(a=gl(2,5,10),b=1:10,x=rnorm(10)) names(mydata) mydata$a mydata$b mydata$x attach(mydata) a b x detach(mydata)
Quand les donnťes sont trŤs peu nombreuses, on peut les entrer directement dans un vecteur (comme on l'a fait jusqu'ici) avec la fonction 'c'.
Les fonctions scan et read.table permettent de lire des donnťes enregistrťes dans des fichiers textes.
scan lit une suite de donnťes dans un vecteur.
Avec un ťditeur de texte, crťez un fichier datafile1.txt contenant:
3.4 5.6 2.1 6.7 8.9
Puis, dans R, entrez:
scores<-scan('datafile1.txt')
On peut ťgalement entrer des donnťes directement en ligne de commande :
scores<-scan('')
La fonction read.table lit des donnťes prťsentťes sous forme tabulaire (par ex. les fichiers .csv enregistrťs par Excel) et renvoie un data.frame.
Crťez un fichier datafile2.txt contenant:
sujet groupe score s1 exp 3 s2 exp 4 s3 exp 6 s4 cont 7 s5 cont 8
Puis importez le dans R:
a<-read.table('datafile2.txt',header=T)
a
R dispose d'un ťditeur de data.frame trŤs limitť:
scores<-edit(data.frame(a))
scan et read.table ne lisent que des fichiers textes, Le package 'foreign' permet de lire directement certains fichiers de donnťes binaires provenant de SPSS, SAS, ...
library(help='foreign')
Mentionnons ťgalement l'existence de packages permettant d'accťder ŗ des informations stockťes dans des bases de donnťes (MySQL, Oracle...).
Cette section a pour but d'illustrer quelques concepts fondamentaux de la statistique infťrentielle, et de prťsenter les principales fonctions de R pour le traitement statistique des donnťes recueillies lors d'un protocole expťrimental.
runif(10) # distribution uniforme rnorm(10) # distribution normale rnorm(10,mean=100) rbinom(10,size=1,prob=.5) # distribution binomiale
La fonction rnorm gťnŤre des nombres alťatoires distribuťs selon une loi normale. En augmentant le nombre d'ťchantillons gťnťrťs (de 10 ŗ 10000), on constate que la distribution des valeurs obtenues se rapproche de plus en plus d'une distribution normale continue :
s1=rnorm(10,mean=2) summary(s1) s2=rnorm(100,mean=2) summary(s2) s3=rnorm(10000,mean=2) summary(s3) par(mfrow=c(3,3)) # organisation des graphiques selon une matrice 3 x 3 hist(s1) # histogrammes hist(s2) hist(s3) # graphes en ťvitant le chevauchement des points de mÍme coordonnťes stripchart(s1,method='jitter',vert=T,pch=16) stripchart(s2,method='jitter',vert=T,pch=16) stripchart(s3,method='jitter',vert=T,pch='.') plot(density(s1)) # fonction de densitť x=seq(-5,5,by=.01) # vecteur de coordonnťes normťes pour les abscisses lines(x,dnorm(x,mean=2),col=2) plot(density(s2)) lines(x,dnorm(x,mean=2),col=2) plot(density(s3)) lines(x,dnorm(x,mean=2),col=2)
En premiŤre approximation, la distribution thťorique de la taille des individus de sexe masculin, franÁais, et dans la tranche d'‚ge 20-35 ans,suit une loi normale de moyenne 170 et d'ťcart-type 10.
On peut donc non seulement situer un individu, ou un groupe d'individus, dans cette distribution, mais ťgalement ťvaluer la probabilitť qu'un individu choisi au hasard parmi la population entiŤre mesure moins de 185 cm, ou plus de 198 cm, ou ait une taille comprise entre 174 et 186 cm.
Lorsque l'on ne dispose pas des tables de lois normales N(m;s2) (il y en a une infinitť puisqu'il y a 2 paramŤtres libres), on utilise la loi normale centrťe-rťduite N(0;12) (encore appelťe loi Z), dont la table est disponible la plupart des manuels ou bien sur le web. Cependant R fournit directement les tables des lois normales, par l'intermťdiaire de la commande pnorm, qui prend en arguments la valeur repŤre, la moyenne et l'ťcart-type thťoriques.
taille=seq(130,210,by=1)
plot(taille,dnorm(taille,mean=170,sd=10),type='b',col="red")
pnorm(185,mean=170,sd=10)
abline(v=185,col=4)
text(185,.012,paste("P(X<185)=",signif(p,3)),col=4,pos=2,cex=.6)
p=pnorm(198,mean=170,sd=10)
abline(v=198,col=4)
text(198,.002,paste("P(X>198)=",round(1-p,3)),col=4,pos=4,cex=.6)
La probabilitť qu'un individu choisi au hasard parmi la population entiŤre mesure moins de 185 cm ( P(X < 185) ) est de 0.933 (obtenu par pnorm(185,mean=170,sd=10)). La probabilitť qu'un individu mesure plus de 198 cm est de 0.003 (1-P(X < 198 ), et la probabilitť que sa taille soit comprise entre 174 et 186 est 0.290 ( P(X < 186)-P(X < 174) ).
On constate que la probabilitť qu'un individu choisi alťatoirement dans une population de moyenne 170 Ī 10 mesure plus de 198 cm est trŤs faible. C'est sur la base de ce calcul de probabilitťs que repose le test de typicalitť, ou ``test Z'' : un groupe d'individus (i.e. un ťchantillon) sera dťclarť atypique ou non reprťsentatif de la population parente dont il est issu, lorsqu'il a une position au moins aussi extrÍme qu'une certaine position de rťfťrence, correspondant en gťnťral ŗ la probabilitť 0.05.
R permet ťgalement de gťnťrer d'autres distributions de probabilitťs, notamment la loi binomiale, les lois statistiques telles que le t de Student, le F de Fisher-Snedecor, le chi-deux ( c2 ), etc. On peut ainsi voir dans l'exemple qui suit que la distribution du t de Student tend vers la loi normale lorsque la taille de l'ťchantillon est suffisamment grande (dans cet exemple, on a manipulť le degrť de libertť df, donnť en argument de la fonction dt).
?pnorm
?pt
?pbinom
help.search('distribution')
pnorm(2)
pt(3,df=10) # fonction de rťpartition de la loi du t de Student
qnorm(.99) # donne la valeur associťe au 99Ťme centile d'une distribution normale
t<--50:50/10
plot(dnorm(t),type='l',col='red')
par(new=T) # le prochain graphe sera superposť au prťcťdent
plot(dt(t,df=5),type='l')
Imaginons que vous disposiez d'une piŤce dont vous vous demandez si elle est baisťe. Vous prťvoyez de la lancer 10 fois ŗ pile ou face. A partir de quelle proportion relative d'essais face/pile (ou l'inverse) considťrerez- vous que la piŤces est truquťe ?
Si la piŤce n'est pas truquťe, le nombre de ``pile'' suit une loi binomiale.
plot(dbinom(0:10,rep(10,11),prob=1/2),type='h') hist(rbinom(100,10,.5)) hist(rbinom(1000,10,.5)) hist(rbinom(10000,10,.5))
Supposez que vous tiriez ŗ pile ou face 10 fois de suite, et que la piŤce retombe 8 fois sur 'pile'. Quelle la probabilitť d'observer cela si la piŤce n'est pas biaisťe ?
binom.test(8,10) prop.test(8,10,1/2) # test approchť
Pour illustrer cela, nous allons utiliser les donnťes issues d'une population d'enfants de sexe masculin ‚gťs de 11 ŗ 16 ans.
taille<-scan('') # saisie manuelle des donnťes
1: 172 155 160 142 157 142 148 180 167 165
11:
Read 10 items # indicateur de fin d'entrťe-sortie gťnťrť par R
poids<-scan('')
1: 50.5 38.1 57.3 39.3 46.1 37.1 45.9 66.3 60 50.5
11:
Read 10 items
plot(poids~taille)
r<-lm(poids~taille) # modŤle linťaire (x,y)
summary(r) # diagnostic de la rťgression
abline(r) # tracť de la droite de rťgression
-55.1963626 + 175 * 0.6568411 # "prťdiction" pour taille=175 cm
predict(r,list(taille=c(175))
Ensuite, ŗ partir de la connaissance de cette liaison linťaire, on peut se demander quelle serait le poids thťorique (non observť) d'un individu dont on ne connaÓt que la taille : c'est le domaine de la rťgression linťaire. L'affichage des paramŤtres de la droite de rťgression donne la relation poids = 0.657 x taille - 55.196. Ainsi, on peut prťdire que le poids d'un enfant mesurant 175 cm sera de 59.8 kg.
Le rťsumť statistique des principaux indicateurs descriptifs de position et de dispersion peut Ítre obtenu ŗ l'aide des fonctions mean, sd, median ; la fonction summary donne un rťsumť plus complet - par exemple, lorsqu'il s'agit d'un vecteur, elle indique la moyenne et la mťdiane, ainsi que l'ťtendue et les valeurs des premier et troisiŤme quartiles.
a<-rnorm(100) mean(a) sd(a) # ťcart-type corrigť summary(a) boxplot(a) mean(a,trim=.1) # moyenne sans les 10 % d'observations en fin de vecteur
Les fonctions graphiques standard en 2D - boxplot, plot, hist - ont ťtť vues dans les sections prťcťdentes. La crťation de graphiques personnalisťs sous R est facilitťe par son extrÍme souplesse quant au paramťtrage des graphiques (positionnement, symboles et type de tracťs, etc.). L'utilisation de l'aide en ligne est vivement recommandťe.
Pour les graphiques en trois dimensions (z ťtant une matrice de dim 3), on pourra utiliser les fonctions image et contour :
x=1:10 y=1:10 z=outer(x,y,"*") persp(x,y,z) image(z) contour(z)
Il est possible de dťfinir ses propres fonctions sous Ret d'enrichir ainsi le langage.
Par exemple, Rne possŤde pas de fonction pour calculer l'erreur-type (s/÷(N)). On peut en dťfinir une de la maniŤre suivante :
se <- function (x) { sd(x)/sqrt(length(x)) }
L'exemple suivant permet de calculer la moyenne arithmťtique aprŤs suppression des valeurs atypiques, i.e. supťrieures ŗ 2 ťcart-types de la moyenne :
clmean <- function (x) {
m<-mean(x)
d<-sqrt(var(x))
threshold<-2
mean(x[(x-m)/d<threshold])
}
a<-c(rnorm(100),5)
mean(a)
clmean(a)
On peut lire le code des fonctions existantes:
clmean ls t.test methods(t.test) getAnywhere(t.test.default)
Ce chapitre a pour but de prťsenter de maniŤre non exhaustive certains tests statistiques employťs frťquemment en statistique infťrentielle.
Comme on l'a vu prťcťdemment (voir section 4.1), la dťtermination des seuils de significativitť (p) se fait gr‚ce aux fonctions associťes ŗ chaque distribution (voir section 4.1).
1-pnorm(167,mean=150,sd=10) 1-pbinom(8,10,0.5)
Soit le tableau de contingence A x B suivant ŗ analyser :
| A1 | A2 | A3 | |
| B1 | 13 | 24 | 20 |
| B2 | 10 | 7 | 18 |
Le calcul du test du c2 associť ŗ ce tableau s'effectue de la maniŤre suivante :
a<-scan('')
1: 13 24 20
4: 10 7 18
7:
Read 6 items
chisq.test(matrix(a,2,3,byrow=T))
a<-10+rnorm(10,sd=10) t.test(a,conf.level=.01)
Si l'hypothŤse de normalitť n'est pas soutenable, le test de Wilcoxon (non-paramťtrique) peut Ítre utilisť ŗ l'aide de la fonction wilcox.test : ce test des signes permet de dťterminer si la mťdiane du groupe peut Ítre considťrťe comme significativement diffťrente de 0.
Ce sont les mÍmes fonctions - t.test (test paramťtrique) et wilcox.test (test non paramťtrique) - qui permettent la comparaison entre deux groupes ; dans ce cas, on passe en arguments les deux groupes :
a<-rnorm(10) b<-rnorm(10,mean=1) t.test(a,b) wilcox.test(a,b) c<-c(a,b) x<-gl(2,10,20) t.test(c~x) wilcox.test(c~x)
Lorsque l'on est en prťsence d'un ensemble de k observations indťpendantes (un seul facteur inter-sujets), on peut comparer leurs moyennes respectives ŗ l'aide de la fonction aov (ou selon un modŤle linťaire gťnťral, avec la fonction lm).
x<-rnorm(100) a<-gl(4,25,100) plot(x~a) r<-aov(x~a) anova(r) pairwise.t.test(x,a) t.test(x[a==1],x[a==2])
Avec deux facteurs inter-sujets, le principe d'analyse est le mÍme, mais on ťtudie ťgalement l'interaction entre les deux facteurs.
x<-rnorm(100) a<-gl(2,50,100) b<-gl(2,25,100) plot(x~factor(a:b)) interaction.plot(a,b,x) l<-aov(x~a*b) anova(l)
Avec un seul facteur intra-sujet, on procŤdera ainsi :
subject<-gl(10,3,30) cond<-gl(3,1,30) x<-rnorm(30) interaction.plot(cond,subject,x) summary(aov(x~cond+Error(subject/cond))
Avec deux facteurs intra, la dťmarche est ŗ peu prŤs identique :
subject<-gl(10,4,40) cond1<-gl(2,1,40) cond2<-gl(2,2,40) table(cond1,cond2) x<-rnorm(40) plot(x~factor(cond1:cond2)) interaction.plot(cond1,cond2,x) interaction.plot(cond1,subject,x) interaction.plot(cond2,subject,x) summary(aov(x~cond1*cond2+Error(subject/(cond1*cond2))))
Comme nous l'avons vu dans le cas des distributions conjointes (cf. section 4.1.2), la dťmarche pour effectuer de la rťgression linťaire est la suivante :
a<-rnorm(100) b<-2*a+rnorm(100) plot(b~a) r<-lm(b~a) anova(r) abline(r)
a<-rnorm(100) b<-2*a+rnorm(100) c<-5*a+rnorm(100) pairs(cbind(a,b,c)) summary(lm(c~a*b))
Ces exemples proviennent principalement du site web ``Analyse Statistique des Donnťes en Psychologie (ASDP)'' de l'UFR de Psychologie de l'universitť Paris 5 (piaget.psycho.univ-paris5.fr/, lien ``Analyse des Donnťes'' puis ``Donnťes'').
Lors d'une expťrimentation mťdicale, on a relevť le temps de sommeil T de 10 patients (facteur Sujet) sous l'effet de deux mťdicaments (d'oý le facteur Mťdicament M). Chaque sujet a pris successivement l'un et l'autre des deux mťdicaments.
Source
Student (1908) The probable error of a mean, Biometrika, VI, 1-25.
Donnťes
Fichier sommeil.txt
Question
Ces donnťes ont ťtť recueillies pour tester l'hypothŤse que le mťdicament m2 est plus efficace que le mťdicament m1. Est-ce le cas†?
Une solution Voir l'exemple de script listť en A.1 et B.1 (Statistica).
Lors d'une expťrimentation pťdagogique, on dťsire comparer l'efficacitť de quatre mťthodes d'enseignements.
On dispose des notes obtenues ŗ un examen par quatre groupes d'ťlŤves ayant chacun reÁu un des 4 types d'enseignements.
Source:
Donnťes fictives.
Donnťes
Fichier pedago.txt
Questions
Comparer les rťsultats obtenus en fonction des mťthodes.
Une solution Voir l'exemple de script listť en A.2 et B.2 (Statistica).
Une recherche a portť sur la "pseudo-nťgligence" qu'on observe chez des sujets normaux. Ce nom provient des similaritťs qu'elle prťsente avec l'hťmi-nťgligence (atteinte de la moitiť du champ visuel) de sujets atteints d'une lťsion cťrťbrale. La t‚che des sujets consiste ŗ dťterminer le milieu subjectif d'une baguette de 24cm avec la seule aide d'informations kinesthťsiques. La pseudo-nťgligence se traduit par une dťviation systťmatique vers la droite (pour les droitiers) de ce milieu subjectif par rapport au milieu objectif de la baguette.
Les donnťes portent sur 24 femmes droitiŤres (facteur S) rťparties selon 2 conditions (12 sujets pour chacune): active (c1) oý le sujet peut librement dťplacer son doigt posť sur un curseur mobile le long de la baguette; ou passive (c2) oý le sujet commande un moteur dťclenchant le mouvement de la baguette dans un sens ou dans l'autre, alors que son doigt ne bouge pas (facteur C). Chaque sujet exťcute cette t‚che dans 6 situations expťrimentales obtenues par le croisement de: la main utilisťe, gauche (m1) ou droite (m2); et l'orientation du regard, 30į ŗ gauche (o1), 0į (o2) ou 30į ŗ droite (o3) (facteurs M et O). Pour chaque sujet et chaque situation on mesure la dťviation en cm entre le milieu subjectif et le milieu objectif de la baguette. Une dťviation ŗ droite est notťe par une valeur positive, ŗ gauche par une valeur nťgative.
On s'intťresse ici ŗ l'effet de la condition (C) lorsque le sujet utilise sa main habituelle (m2) (Rappel†: tous les sujets sont droitiers) et lorsqu'il se trouve en face du milieu de la baguette (avec l'orientation ŗ 0 degrťs)
Source
Chokron, Imbert (1993) - Egocentric reference and asymmetric perception of space, Neuropsychologia, 31, 3, 267-275. D'aprŤs J.M. Bernard (1994) - Structure des donnťes, d
Donnťes fichier neglige2.txt
Questions
Importer ces donnťes, les visualiser, comparer les groupes. Conclusion?
Une solution
Voir l'exemple de script listť en A.3 et B.3 (Statistica).
Étude rťalisťe au USA sur les origines des stťrťotypes liťs au sexe. 35 familles choisies au hasard et ayant une fille ainťe (ou fille unique) en ``ninth grade'' (TroisiŤme).
Le pŤre a rťpondu ŗ un questionnaire sur ses intťrÍts pour le sport, notť sur une ťchelle numťrique de 0 ŗ 50 (FATH)
La mŤre a rťpondu au mÍme questionnaire (MOTH)
Le professeur d'ťducation physique de chacune des filles a notť les performances physiques gťnťrales de la fille de 0 ŗ 20 (PROF).
La fille a rťpondu ťgalement au questionnaire d'inťrÍt pour le sport (GIRL).
Source Hays, W.L. (1994) - Statistics, Fort Worth: Harcourt Brace College Publishers (5Ťme ťdition), p.671-672
Donnťes family.txt
Questions Que faire avec ces donnťes?
Une solution Voir l'exemple de script listť en A.4 et B.4 (Statistica).
Source Il s'agit de donnťes en partie fictives, inspirťes d'un exemple de M. Reuchlin.
Donnťes Fichier io.txt
Questions Peut-on dire que l'orientation envisagťe est liťe au sexe chez l'ensemble des lycťens de cette annťe 1980 ?
Une solution Voir l'exemple de script listť en A.5 et B.5 (Statistica).
Nous proposons ici des scripts pour analyser les exemples du chapitre 6. Il y a plusieurs maniŤres de rťsoudre le mÍme problŤme avec R. Par consťquent, vos scripts peuvent diffťrer.
sommeil<-read.table('sommeil1.txt',header=T)
sommeil
attach(sommeil)
summary(M1)
summary(M2)
plot(M1,M2,xlim=c(0,10),ylim=c(0,10),col=2)
identify(M1,M2,SOMMEIL)
abline(0,1)
stripchart(M2-M1,method='stack')
t.test(M2-M1)
t.test(M1,M2,paired=T)
detach()
a<-read.table('pedago.txt')
attach(a)
boxplot(notes~pedago)
stripchart(notes~pedago,method='stack',vertical=T)
tapply(notes,pedago,mean)
tapply(notes,pedago,sd)
tapply(notes,pedago,summary)
barplot(t(tapply(notes,pedago,mean)))
m<-aov(notes~pedago)
summary(m)
TukeyHSD(m)
plot(TukeyHSD(m))
d<-read.table('neglige4.txt')
x<-d$V1
a<-gl(2,12,24)
b<-gl(2,6,24)
table(a,b)
tapply(x,list(a=a,b=b),mean)
interaction.plot(a,b,x)
l<-aov(x~a*b)
summary(l)
model.tables(l,se=T)
t.test(x[a==1 & b==1],x[a==1 & b==2])
t.test(x[a==2 & b==1],x[a==2 & b==2])
fam<-read.table('family.txt',header=T)
fam
attach(fam)
data<-as.matrix(fam[,-1])
pairs(data,panel=panel.smooth)
cor(data)
cor.test(FATH,GIRL)
cor.test(MOTH,GIRL)
cor.test(INST,GIRL)
l<-lm(GIRL ~ FATH + MOTH + INST)
summary(l)
detach(fam)
a<-read.table('io.txt',header=T)
attach(a)
table(Sexe,MatiŤre)
chisq.test(table(Sexe,MatiŤre))
De maniŤre gťnťrale, lorsque l'on dispose de simples fichiers texte pour les donnťes, l'importation des donnťes se fait ŗ l'aide de la commande Fichier \triangleright Importer des donnťes \triangleright Rapide. Le cas ťchťant, lorsque le fichier de donnťes est dťjŗ sous le format Statistica (extension .sta), il suffit simplement d'utiliser la commande Fichier \triangleright Ouvrir des donnťes.
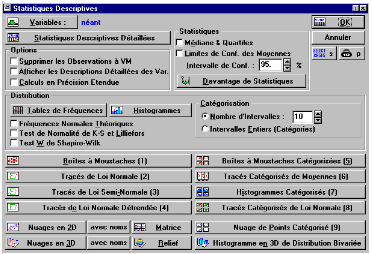
Il est intťressant de visualiser les donnťes sous forme de "boÓtes ŗ moustaches" (cf Fig. B.2) ; pour cela, il suffit de cliquer sur le bouton BOITE A MOUSTACHES, et de sťlectionner ensuite l'option Mťdiane/Quartile/Etendue dans la boite de dialogue suivante.
Ensuite, on peut lancer le test t sur le panneau initial (s'il n'est plus visible, cliquer sur la petite boÓte de dialogue Reprendre analyse ou SUITE si vous Ítes sur la derniŤre fenÍtre graphique), en appuyant sur le bouton TESTS.
|
|
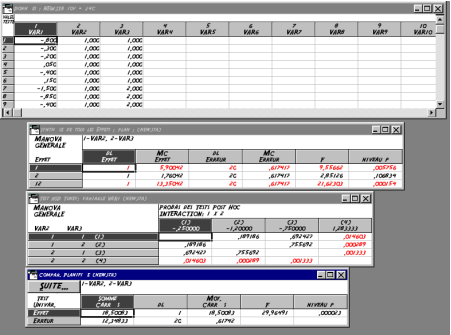
Le rťsultat de l'analyse s'affiche dans une nouvelle fenÍtre de sortie (cf Fig. B.1). A la lecture des rťsultats, on voit que le test t est significatif : t = -4,06213, p/2 = ,0014165 (p = ,002833, dl = 9).
|
|
On pourra remarquer que l'analyse aurait abouti au mÍme rťsultat en dťrivant le protocole par diffťrence, et en effectuant un test t contre une moyenne thťorique m = 0 (p = ,0016). Sous Statistica, aller dans Autres tests de significativitť, Diffťrence entre deux moyennes, cocher Moyenne du cas 1 vs. Moyenne de la population 2, M1=-1,56, s1=1,24, n=10, appuyer sur Calculer et lire le seuil p correspondant4.
En supposant que le tableau de donnťes aÓt ťtť correctement saisi (2 colonnes comprenant la VD et la VI sous forme indicťe - 1, 2, 3, 4 - par exemple ; les observations en ligne), il suffit de sťlectionner les variables de l'analyse en cliquant sur le bouton Variables et d'indiquer la colonne contenant la variable indťpendante et celle contenant la variable dťpendante. AprŤs avoir validť, on revient sur l'ťcran prťcťdent, et on indique la liste des facteurs inter (la VI est un facteur de groupe) que l'on veut prendre en compte dans l'analyse en cliquant sur le bouton Liste fact. inter et en indiquant Tous5.
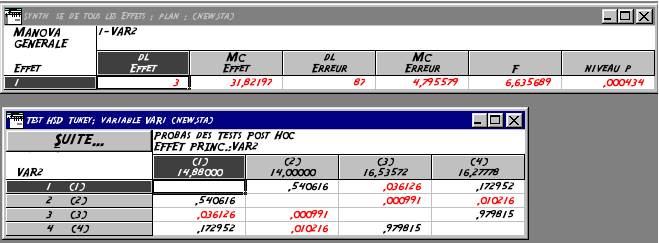
Lorsque l'on valide en appuyant sur la touche OK, le panneau d'analyse de variance s'affiche, le plan d'analyse considťrť (facteurs systťmatique inter, intra etc.) ťtant indiquť dans la partie supťrieure. Lorsqu'on clique sur le bouton Tous les effets, Statistica lance l'analyse de variance d'ordre 1, et une fenÍtre de rťsultats s'affiche. Cette derniŤre comprend un tableau d'ANOVA d'ordre 1 classique, avec le carrť moyen de l'effet et celui de l'erreur (MC effet et MC error), les degrťs de libertťs associťs aux sommes des carrťs (3 et 86), la valeur du F (6,635689), ainsi que le seuil p associť (0,000434) (cf. Fig. B.3). Par dťfaut6, Statistica affiche en rouge les valeurs significatives par rapport aux seuils repŤres (que l'on peut redťfinir dans les options Statistica).
|
|
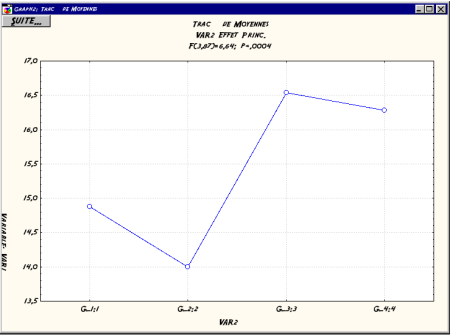
Il est ťgalement possible d'avoir une reprťsentation graphique des moyennes des groupes de sujet en cliquant sur le bouton Comparaison moy., puis en sťlectionnant la sortie graphique, mais par dťfaut ce n'est pas une boÓte ŗ moustache qui est affichťe (cf. Fig. B.4).
|
|
Nous utiliserons comme dans le dossier prťcťdent le module ANOVA/MANOVA, en supposant les donnťes dťjŗ disponibles au bon format et prťsentes dans le tableau de donnťes (3 colonnes comprenant la VD et les 2 VI sous forme indicťe - 1, 2 - par exemple ; les observations en ligne). On dťfinira comme prťcťdemment les variables dťpendantes et indťpendantes, ainsi que les facteurs inter ŗ prendre en compte dans l'analyse (i.e. tous).
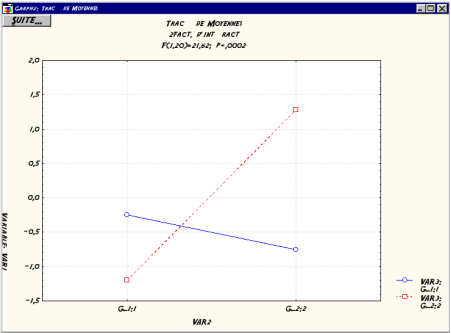
En rťpťtant les mÍmes ťtapes que celles effectuťes dans le dossier Pťdago, on obtient le tableau d'ANOVA d'ordre 2 avec l'effet des deux facteurs systťmatiques et l'interaction entre ces deux facteurs (cf. Fig. B.5). L'interaction entre les deux facteurs, et son seuil de significativitť peuvent Ítre visualisť en cliquant sur le bouton Comparaison moy., puis en sťlectionnant la sortie graphique. Etant donnť qu'il y a deux variables, il faudra indiquer quelle variable sera reprise sur l'axe des abscisses (cf. Fig. B.6).
|
|
En revanche, puisqu'on est dans un cas d'ANOVA ŗ plusieurs facteurs, il faudra analyser les moyennes qui sont significativement diffťrentes prises deux ŗ deux : on utilisera pour cela les comparaisons multiples (non planifiťes) qui sont accessibles en cliquant sur le bouton Tests post-hoc. Le test de Tukey-HSD peut-Ítre utilisť, et on sťlectionnera l'option Diffťrences significatives. Le rťsultat du test s'affiche dans une nouvelle fenÍtre, sous forme d'un tableau indiquant en ligne les comparaison par paire de modalitťs des deux variables7.
On notera que que sous Statistica, le rťsultat du test de Tukey-HSD indique les seuils p pour les diffťrences significatives et non les intervalles de confiance ŗ 95 % comme sous R.
|
|
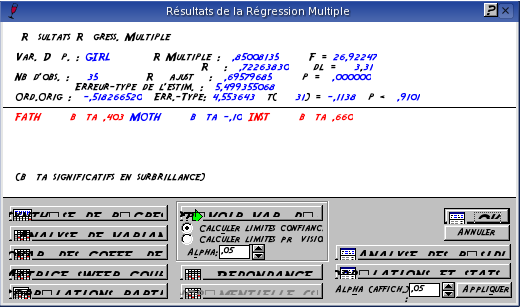
AprŤs avoir cliquer dans le commutateur de modules de Statistica Rťgression multiple (ou menu Analyse \triangleright Autres statistiques \triangleright Rťgression multiple), il faut spťcifier la variable dťpendante (ici les donnťes de la fille), et les variables indťpendantes, i.e. les variables prťdictrices (les 3 autres sťries de donnťes - pŤre, mŤre, prof). Une fois le codage des variables effectuť, valider en appuyant sur OK. Un tableau indiquant les rťsultats de la rťgression multiple - coefficients b, R2 - s'affiche (cf. Fig. B.7).
L'analyse des valeurs prťdites et des rťsidus est obtenue gr‚ce ŗ la commande Analyse des rťsidus dans la fenÍtre Analyse de la rťgression multiple, puis en sťlectionnant Afficher Rťsidus & Prťv..
|
|
Lorsque l'on clique sur OK, un panneau intitulť Rťsultats de l'Analyse des Correspondances apparaÓt et indique dans la partie supťrieure le rťsultat du test du chi-deux : ici, c2=6.66667, dl=2, p=0.357 . Les indicateurs descriptifs concernant le tableau de contingence sont accessibles via le panneau de contrŰle dans la partie infťrieure :
Les contributions au c2 sont indiquťes pour chaque croisement des modalitťs des deux variables en cliquant sur le bouton Contrib. au Chi-deux.
Etant donnť la richesse de l'interface, ou plutŰt des interfaces (cf. infra) de Statistica, nous nous contenterons d'ťvoquer quelques-unes de ses principales fonctionnalitťs, afin que le lecteur soit ŗ mÍme : (1) d'ouvrir ou d'importer un fichier de donnťes, (2) d'effectuer des statistisques descriptives ťlťmentaires, (3) de crťer des reprťsentations graphiques et (4) d'analyser des protocoles simples (cf. ťgalement la section B). De plus amples informations peuvent Ítre obtenues gr‚ce aux manuels de Statistica, ŗ l'aide en ligne, ou aux nombreux tutoriels disponibles sur le web.
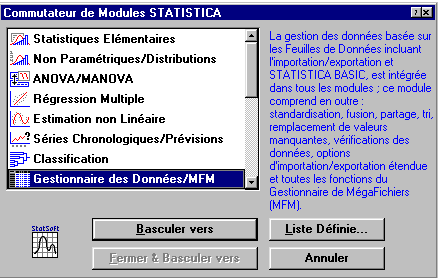
Statistica est un logiciel trŤs puissant permettant de faire de l'analyse descriptive et infťrentielle. Statistica est organisť en diffťrents modules - Statistiques Elťmentaires, ANOVA/MANOVA, etc. -, accessibles au travers du commutateur de modules (cf. Fig. C.1), qui est automatiquement lancť au dťmarrage. Il demeure ensuite accessible dans le menu Analyse \triangleright Autres Statistiques.
|
|
Chaque module correspond en fait ŗ un environnement d'analyse particulier, et l'interface de Statistica (boutons, menus) est spťcifique de chaque module, et des fenÍtres actives (feuille de donnťes, graphique). Lorsque l'on bascule d'un module ŗ l'autre, par exemple de celui des Statistiques Elťmentaires ŗ celui dťdiť ŗ l'analyse de variance ANOVA/MANOVA, il est prťfťrable de fermer le module prťcťdent : utiliser pour cela le bouton Fermer & Basculer vers ; cela ťvitera d'avoir plusieurs fenÍtres Statistica ouverte en mÍme temps.
Lorsqu'il n'y a qu'une seule V.I. ŗ plusieurs modalitťs, on peut coder ses modalitťs dans une autre colonne-variable, qui sert alors de variable de classement. Dans le cas oý on a plusieurs V.I. ŗ plusieurs modalitťs (cas par exemple d'un protocole de mesures rťpťtťes), les variables correspondent en fait au croisement de chaque modalitť de chaque variable. Par exemple, si l'on a 2 V.I. A et B ŗ 2 niveaux (i.e. un plan de type S*A2*B2 ), il y aura 4 colonnes disposťes prťcisemment8 comme suit : a1b1 a1b2 a2b1 a2b2. Il est utile de s'assurer de la bonne disposition des donnťes en affichant un graphique, car si l'ordre des facteurs est inversťs par exemple, il risque d'y avoir des problŤmes lors de l'interprťtation de l'interaction A x B.
L'aide en ligne est gťnťralement bien rťdigťe et indique dans chaque situation (plan avec groupes indťpendants, groupes appariťs, mesures rťpťtťes, plan factoriel, ßplit-plot" etc.) comment organiser les donnťes. N'hťsitez pas ŗ vous y rťfťrer, mÍme pour vťrification.
Il est ťgalement possible de paramťtrer le type de rťsultats ŗ afficher (moyenne, mťdiane, quantiles, ťcart-type etc.), ŗ l'aide du bouton Davantage de Statistiques. En revanche, il faut garder ŗ l'esprit que Statistica ne calcule que des ťcart-types et variances corrigťs9.
|
|
|
|
|
|
D'autres options trŤs utiles sont disponibles ne cliquant sur le bouton Options. La nouvelle boÓte de dialogue qui s'affiche permet en effet de sťlectionner le nombre d'observations ŗ inclure dans le graphique, de spťcifier l'affichage des ťtiquettes d'observations (ce qui permet de repťrer directement une observation sur le graphique par une ťtiquette de type i1, i2, ..., sans avoir ŗ le faire ŗ l'aide de ses coordonnťes).
1www.pallier.org
2christophe.lalanne.free.fr
3Pour ceux qui emploient l'ťditeur Emacs, il existe un package appelť ESS qui fournit la colorisation syntaxique des commandes R, et plein d'autres fonctions utiles (voir stats.ethz.ch/ESS.
4Une autre solution consiste ŗ effectuer le calcul ŗ la main : t(n-1)=([`x]-m)/(s/÷(n)) = -3.97 , et ŗ comparer la valeur aux valeurs repŤres de la table du t : p < .003 (p/2 < .0015)
5On pourrait vouloir restreindre l'analyse ŗ deux conditions seulement, auquel cas on indiquerait les conditions individuelles
6ce n'est le cas lors des comparaisons multiples
7le tableau ťtant une matrice symťtrique de seuils de significativitť p, on peut se contenter de lire la moitiť des valeurs...
8Il faut faire attention ŗ l'ordre, en effet, car Statistica va dťterminer les modalitťs des facteurs ŗ partir de l'ordre dans lequel ils sont rangťs dans la feuille de donnťes ; ainsi, si on rangeait les donnťes sous la forme a1b1 a2b1 a1b2 a2b2, le plan correspondant serait S*B2*A2 , et pire encore si on intervertissait 2 colonnes, on aurait un plan incorrect puisque mťlangeant les facteurs !
9Pour obtenir des ťcart-types et variances
non corrigťs, il faut multiplier les valeurs obtenues par [(n-1)/n] .